Hadoop集群
前置:所有主从节点的java版本,安装路径均一样
项目安排
master 192.168.43.136
slave1 192.168.43.137
slave2 192.168.43.138设置Host映射文件
bash
# cmaster
# 注意:ip和名称之间是tab建,不是空隔
vim /etc/hosts
192.168.43.136 master
192.168.43.137 slave1
192.168.43.138 slave2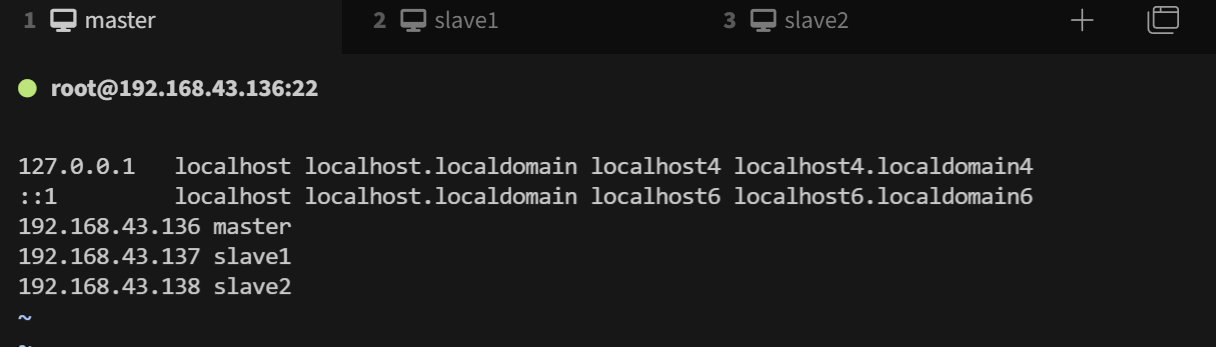
使用ping命令验证是否配置成功
设置集群节点免密登录
在master上执行“ssh-keygen”命令生成公私钥。
第一个提示是询问将公私钥文件存放在哪,直接回车,选择默认位置。 第二个提示是请求用户输入密钥,既然操作的目的就是实现SSH无密钥登录,故此处必须使用空密钥,所谓的空密钥指的是直接回车,不是空格,更不是其他字符。此处请读者务必直接回车,使用空密钥。 第三个提示是要求用户确认刚才输入的密钥,既然刚才是空密钥(直接回车即空),那现在也应为空,直接回车即可。
最后,可通过命令“ls -all /root/.ssh”查看到,SSH密钥文件夹.ssh目录下的确生成了两个文件id_rsa和id_rsa_pub,这两个文件都有用,其中公钥用于加密,私钥用于解密。中间的rsa表示算法为RSA算法。
bash
ssh-keygen
ls -all /root/.ssh
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2检查能否免密登录
bash
# ssh master //用户登录本机网络地址
# ssh slave1 //用户从master远程登录slave1
# ssh slave2 //用户从master远程登录slave2注意:我们搭建的是3节点完全分布式的Hadoop集群,所以3个节点的 /etc/hosts 文件要保持一致。用 scp 命令分发文件到每个节点覆盖原有配置。
bash
scp /etc/hosts slave1:/etc/hosts
scp /etc/hosts slave2:/etc/hosts设置操作系统环境
配置HDFS
xml
vim core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop-3.3.5/etc/hadoop/cloud</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
</configuration>注意 hadoop2配置从节点是在slaves文件中,而hadoop3配置从节点是在workers文件中
bash
vim workers
# 将localhost改为如下配置
slave1
slave2拷贝集群配置至其它服务器
在master机上执行下列命令,将配置好的hadoop从master节点拷贝至slave节点。
bash
cd /root
scp -r hadoop-3.3.5/ slave1:/root/hadoop-3.3.5
scp -r hadoop-3.3.5/ slave2:/root/hadoop-3.3.5在master服务器上格式化主节点:
bash
/root/hadoop-3.3.5/bin/hdfs namenode -format启动Hadoop
bash
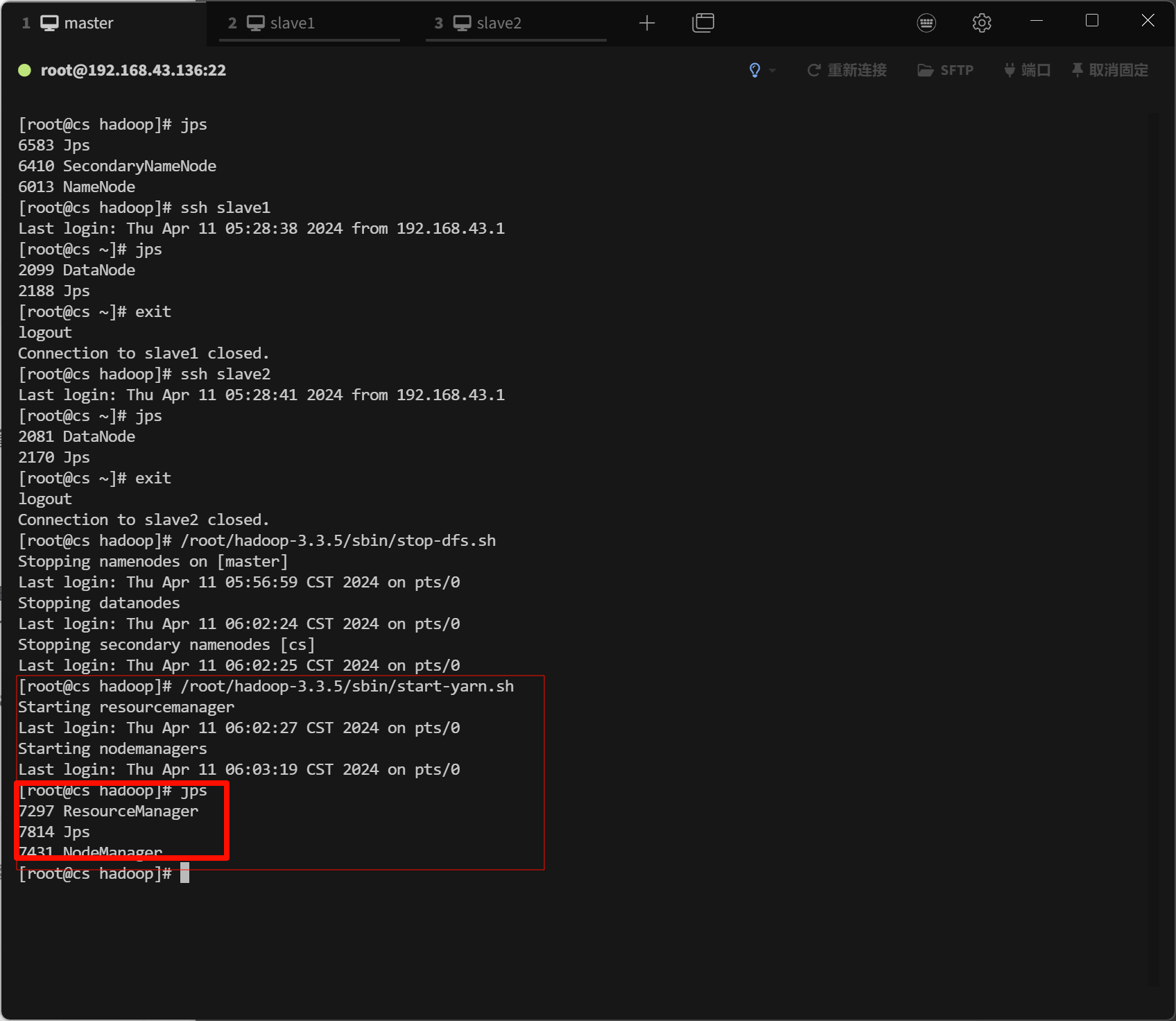
/root/hadoop-3.3.5/sbin/start-dfs.sh通过查看进程的方式验证
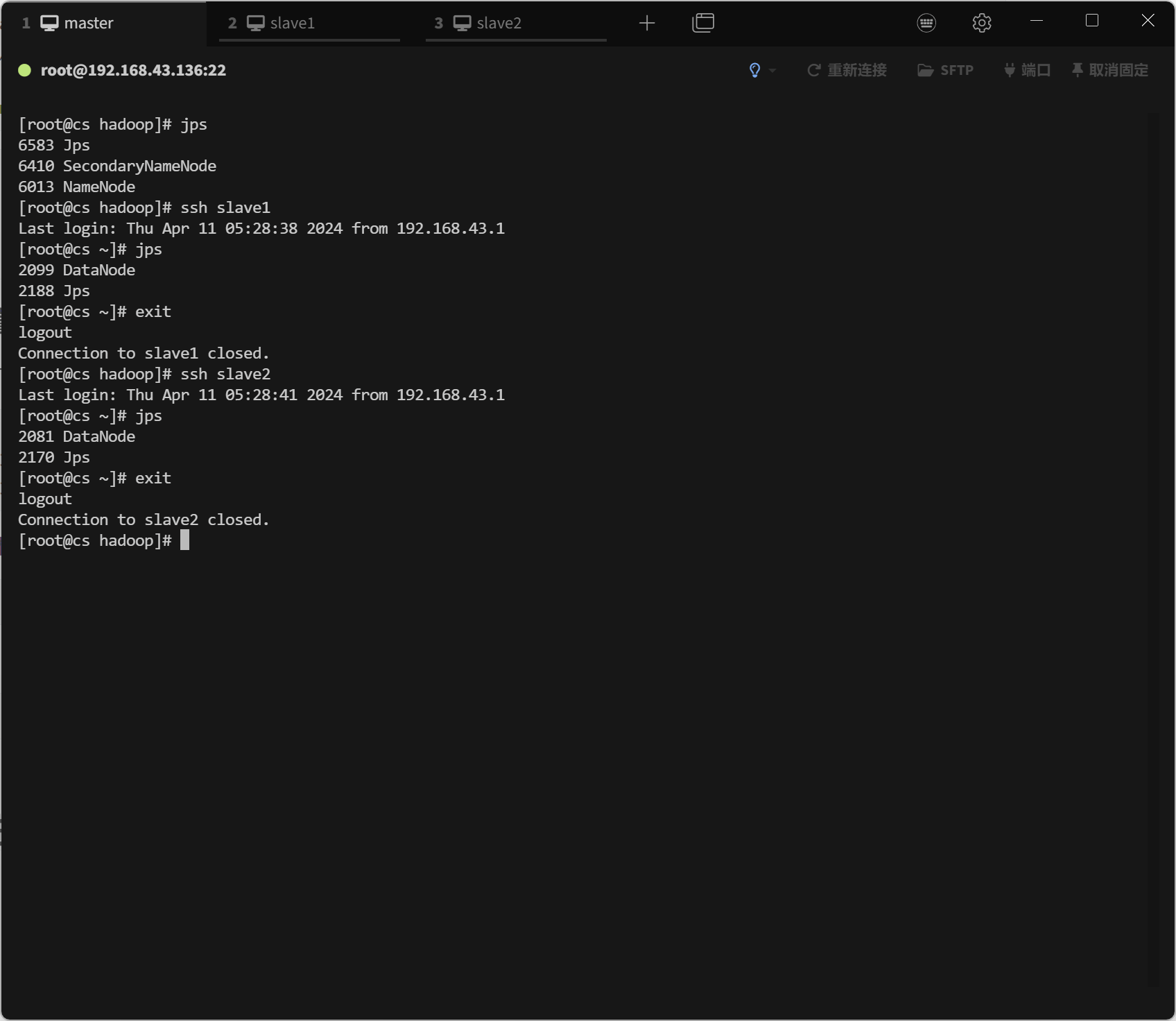
统一启动YARN
bash
/root/hadoop-3.3.5/sbin/start-yarn.sh