Hadoop在win11安装
1 安装并配置jdk-1.8(jdk-8u391)
Java Archive Downloads - Java SE 8u211 and later (oracle.com)
注意:更改jre和jdk路径,不要包含空格和中文
配置java环境变量
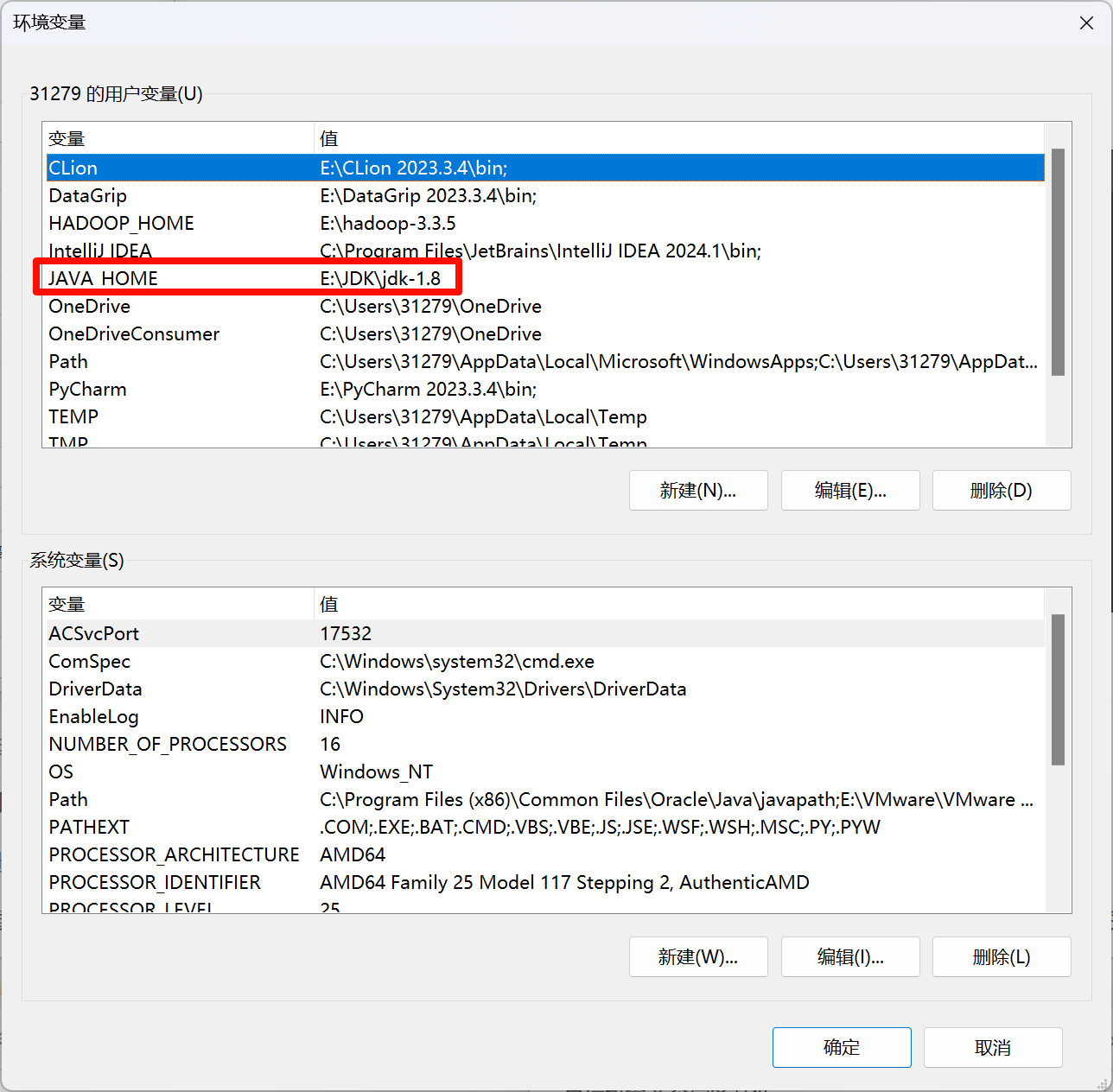
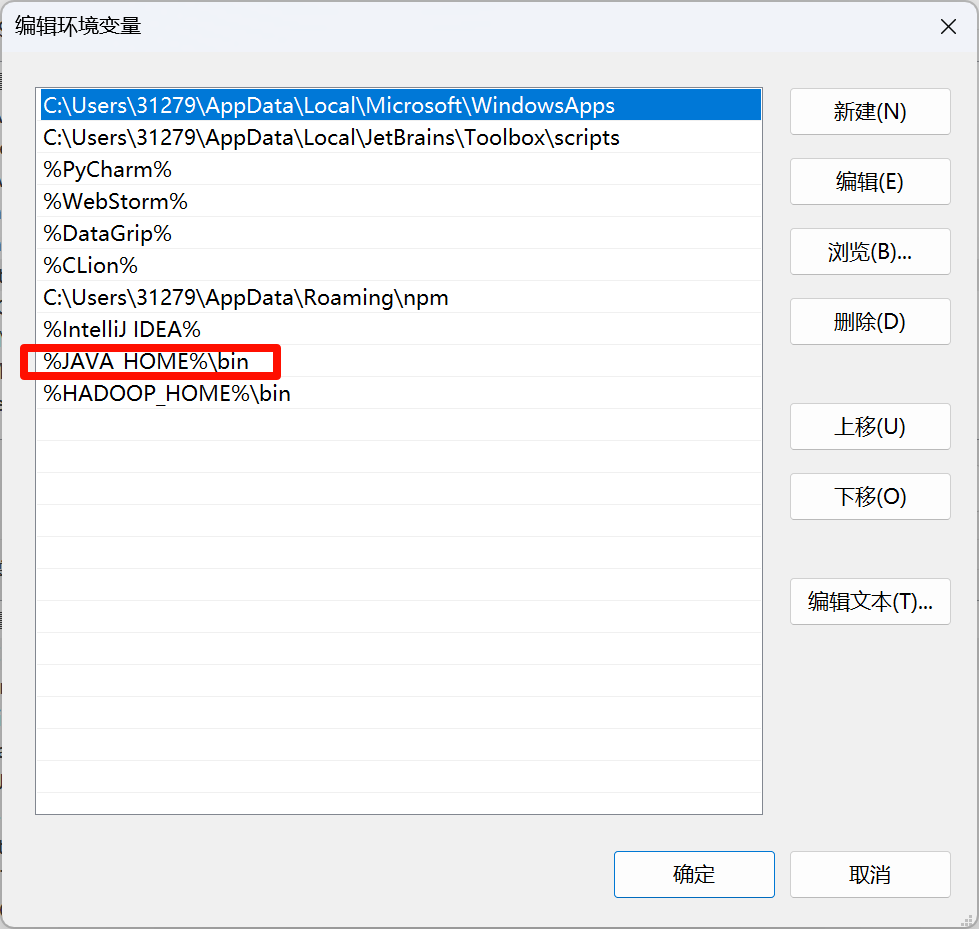
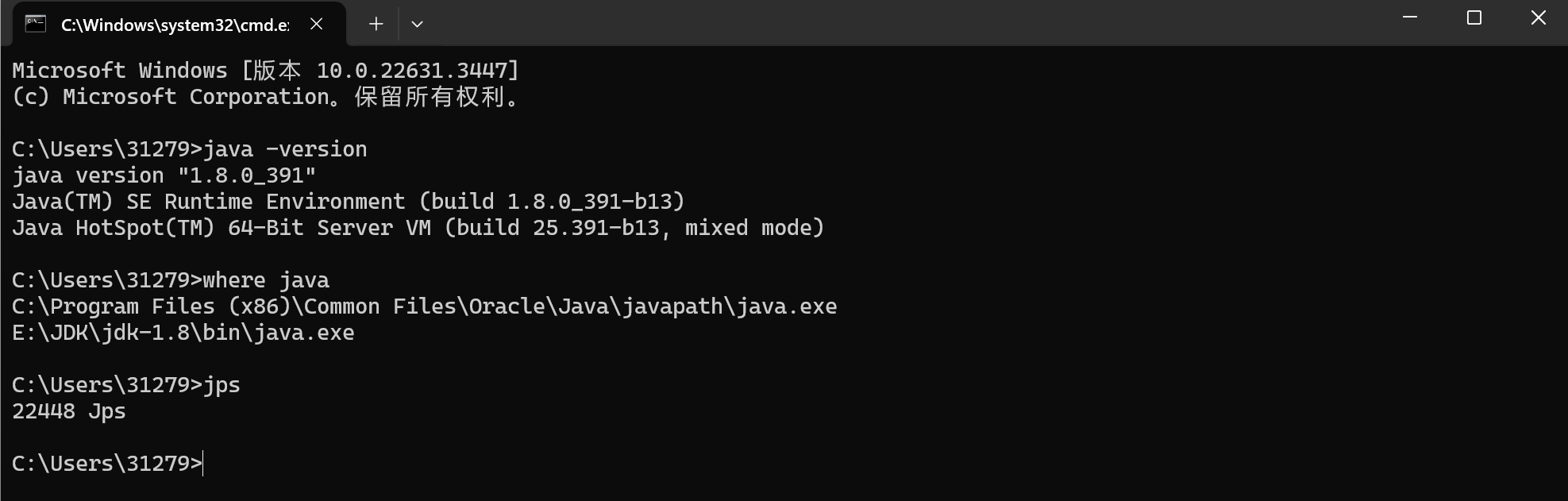
检查是否安装完成
win+r+cmd
2 下载并配置Hadoop
由于Hadoop大部分在linux上使用,所以在win系统上使用还需要下载winutils这个第三方包
GitHub - cdarlint/winutils: winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows
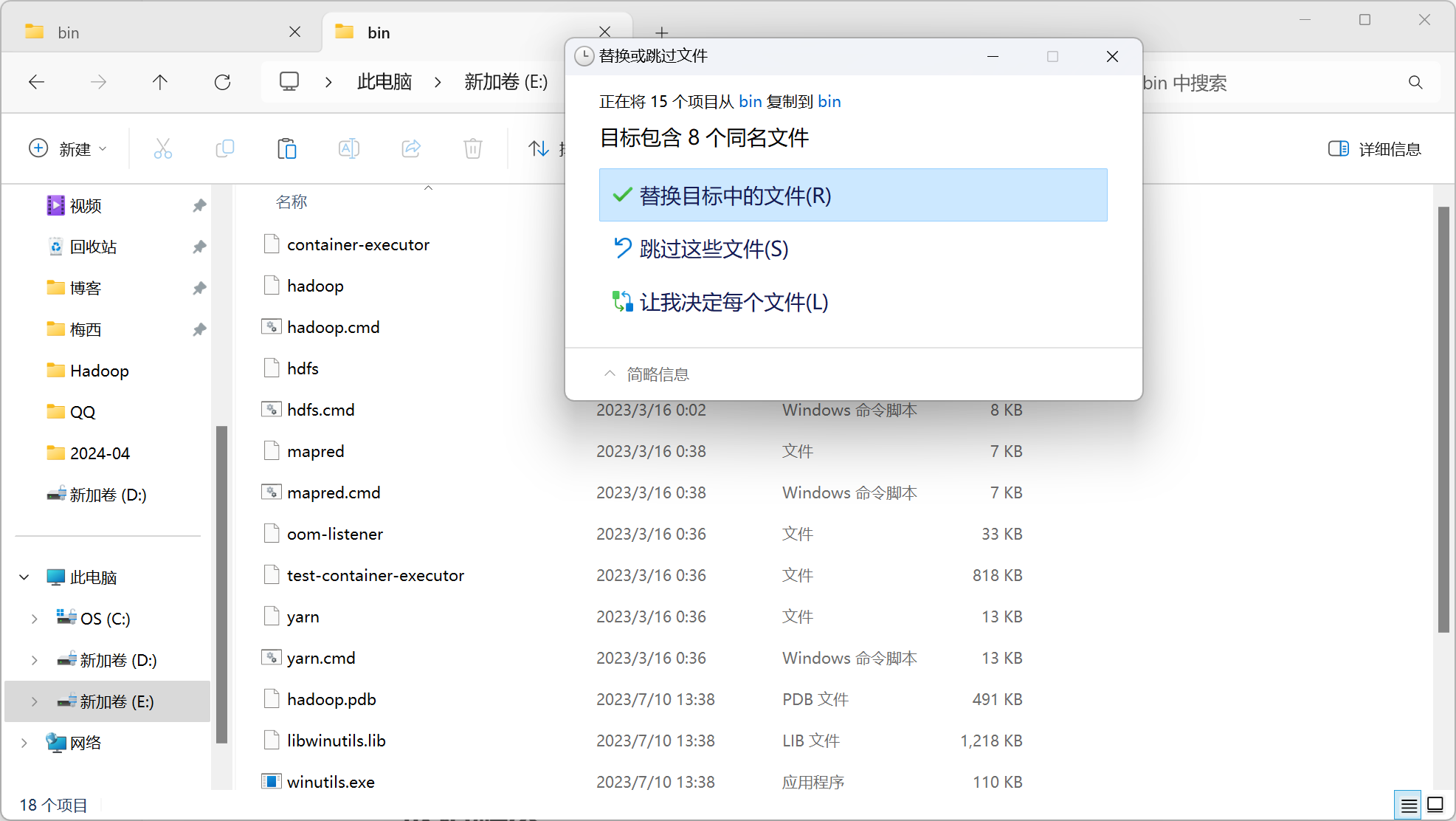
下载对应版本的包含winutiles.exe文件的压缩包,将压缩包里bin里的所有文件替换掉Hadoop的解压缩文件夹里的bin文件夹里文件
配置Hadoop环境变量
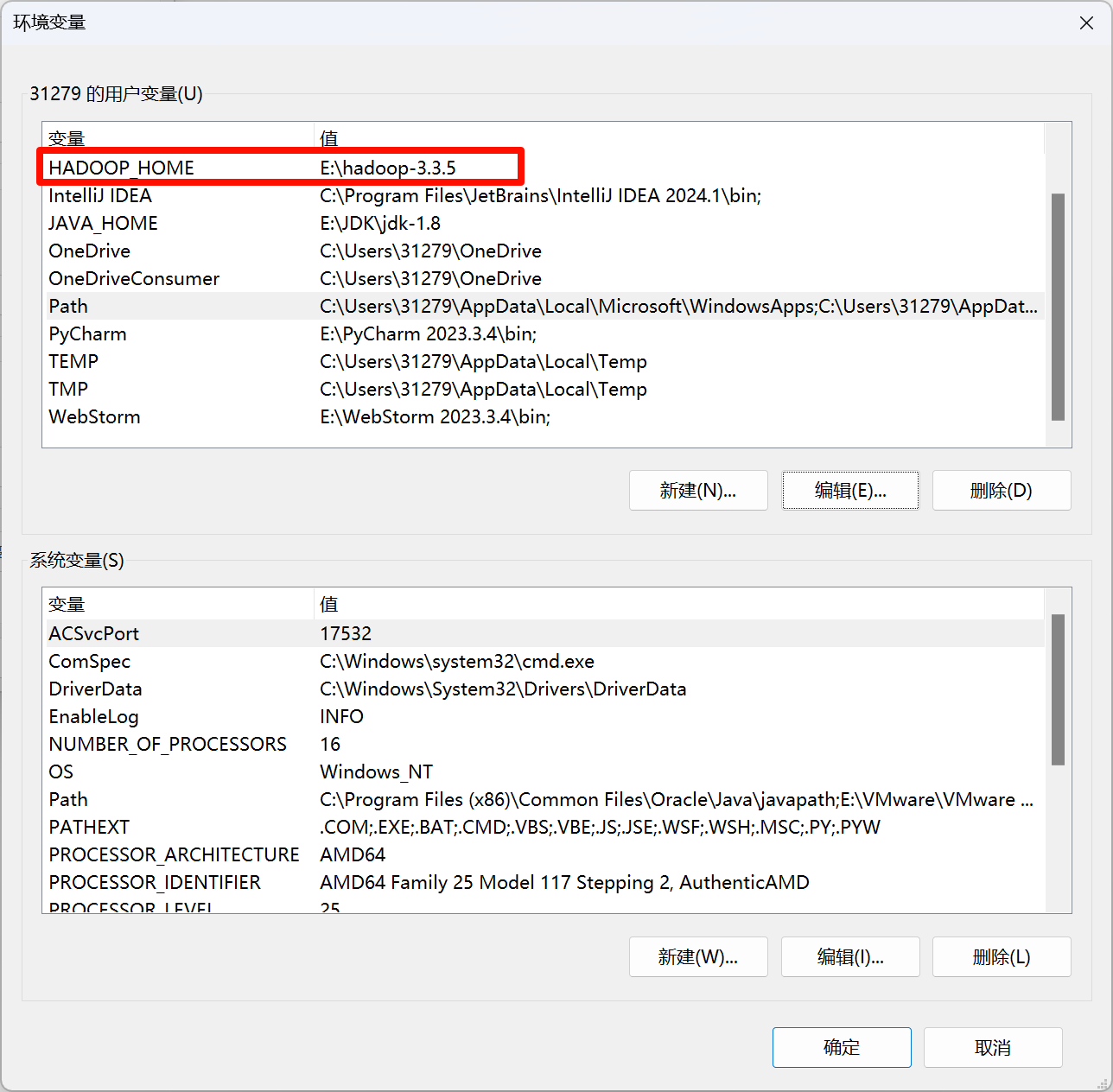
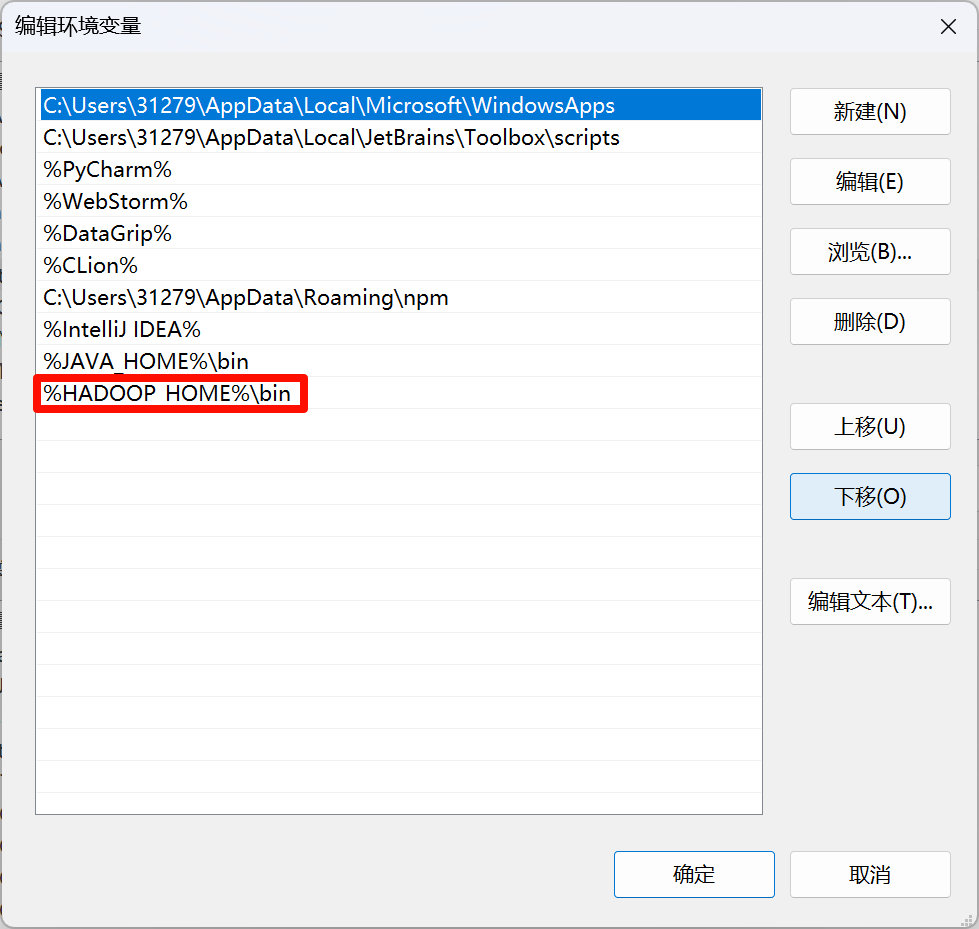
检查是否安装完成
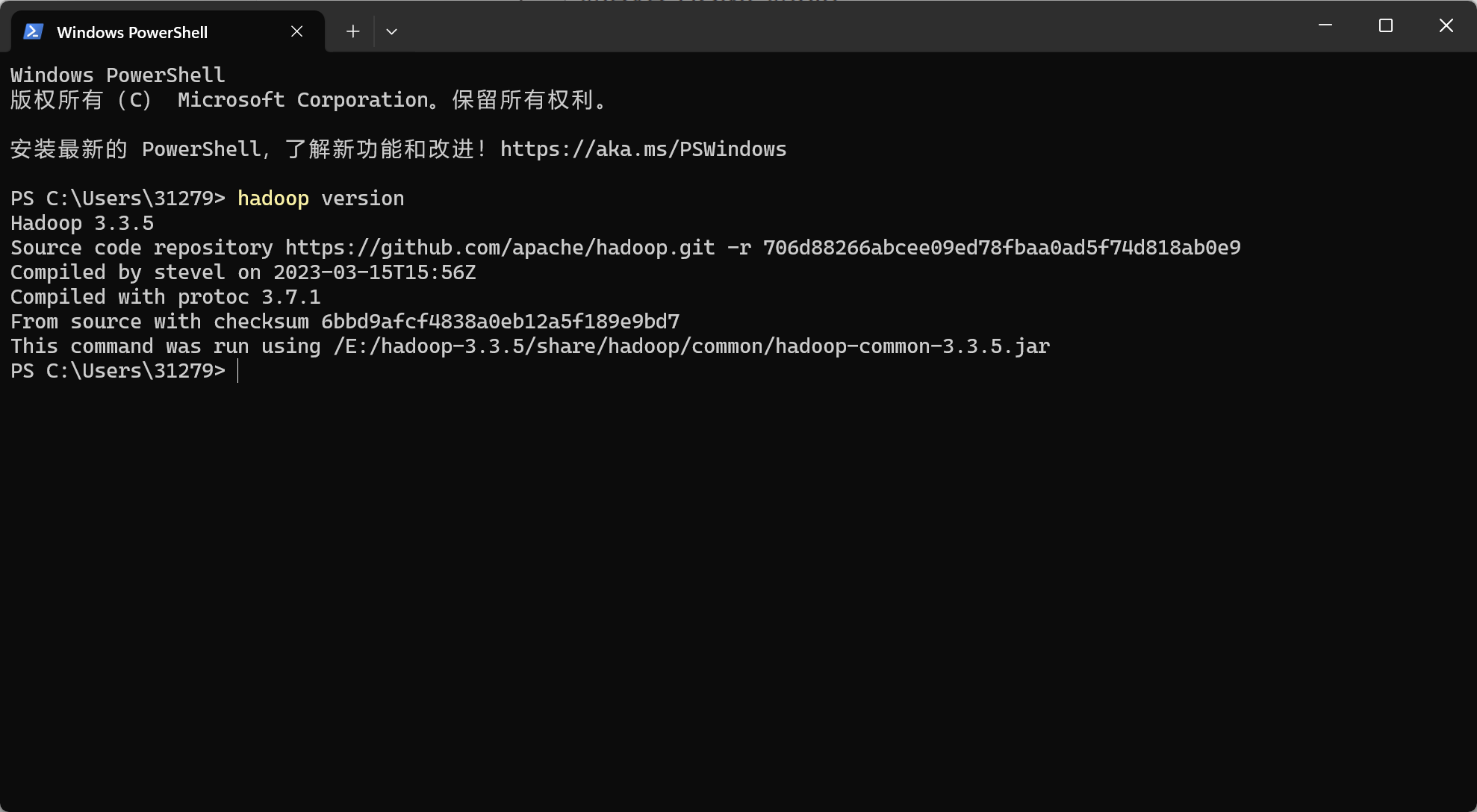
修改Hadoop配置文件
core-site.xml
xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:///E:/hadoop-3.3.5/tmp</value>
</property>
</configuration>hdfs-site.xml
xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///E:/hadoop-3.3.5/data/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///E:/hadoop-3.3.5/data/dfs/datanode</value>
</property>
</configuration>注意:file所指文件保存路径替换成自己设置的namenode和datanode的地址,没有的文件夹要自己去新建,建好文件夹再填这些地址进入配置
mapred-site.xml
xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>yarn-site.xml
xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>格式化namenode
在hadoop安装目录的bin目录下
bash
hadoop namenode -format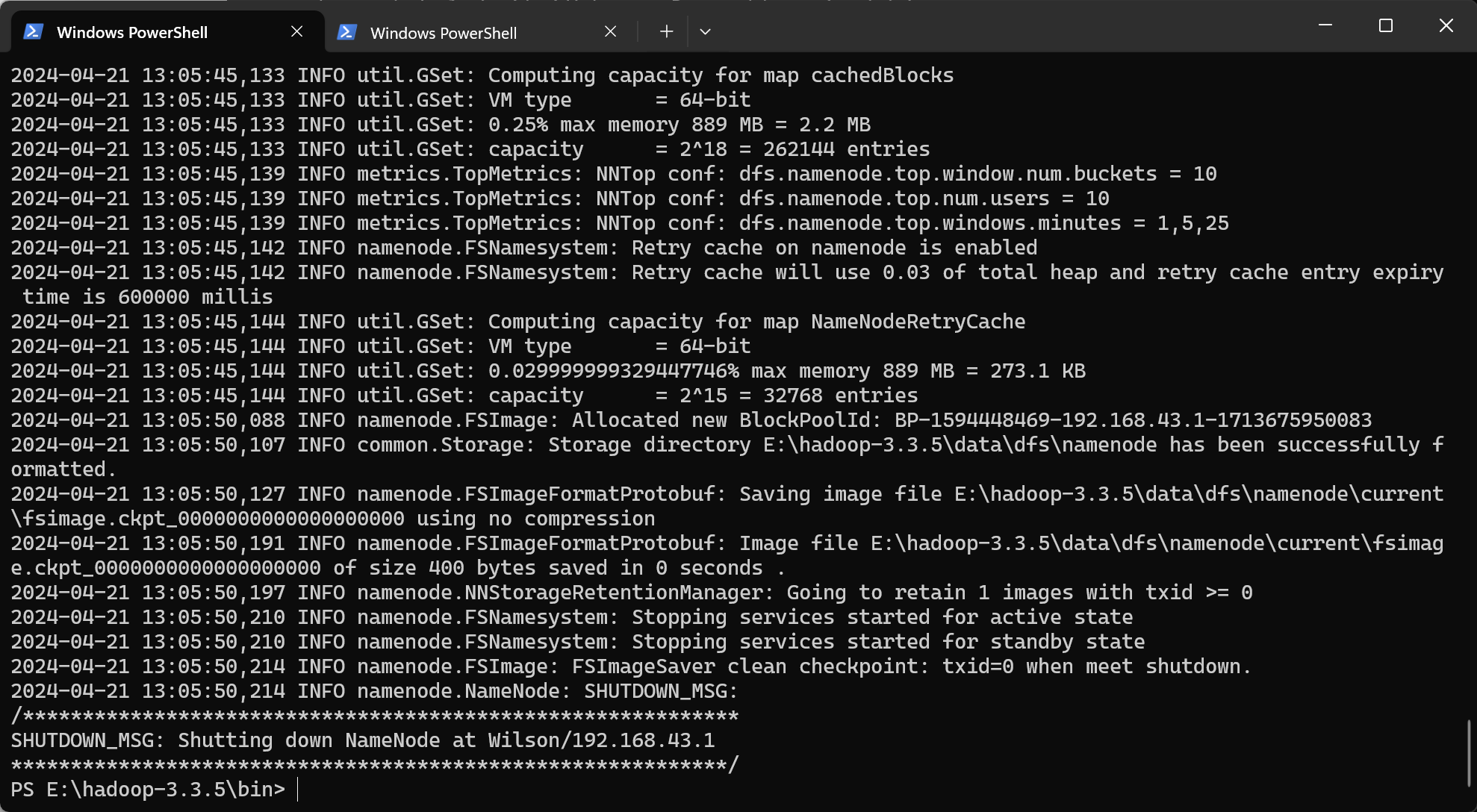
成功格式化后进入hadoop的sbin文件夹内打开各节点
bash
.\start-all.cmd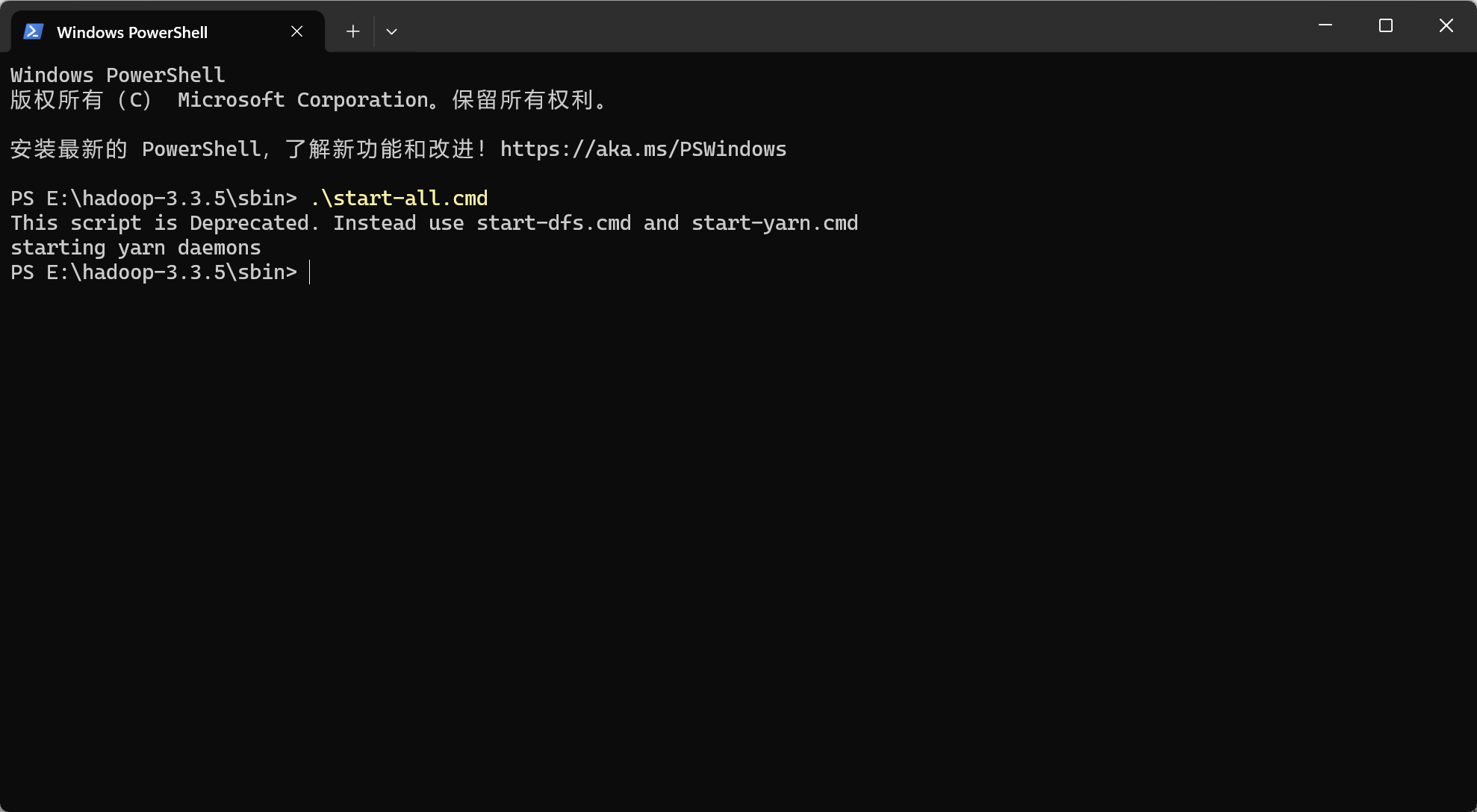
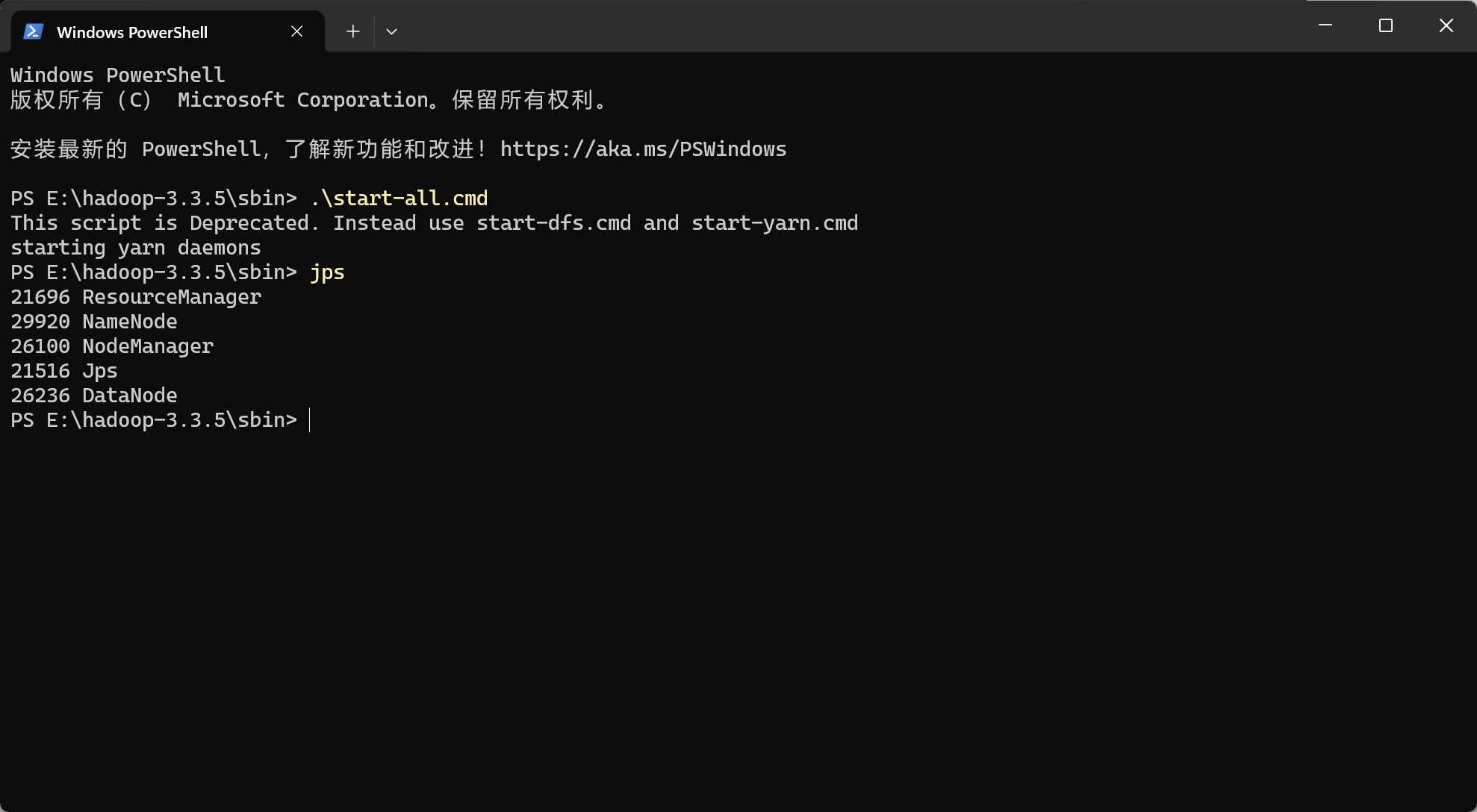
检查是否成功运行4个进程
3 下载并配置Spark
配置Spark环境变量
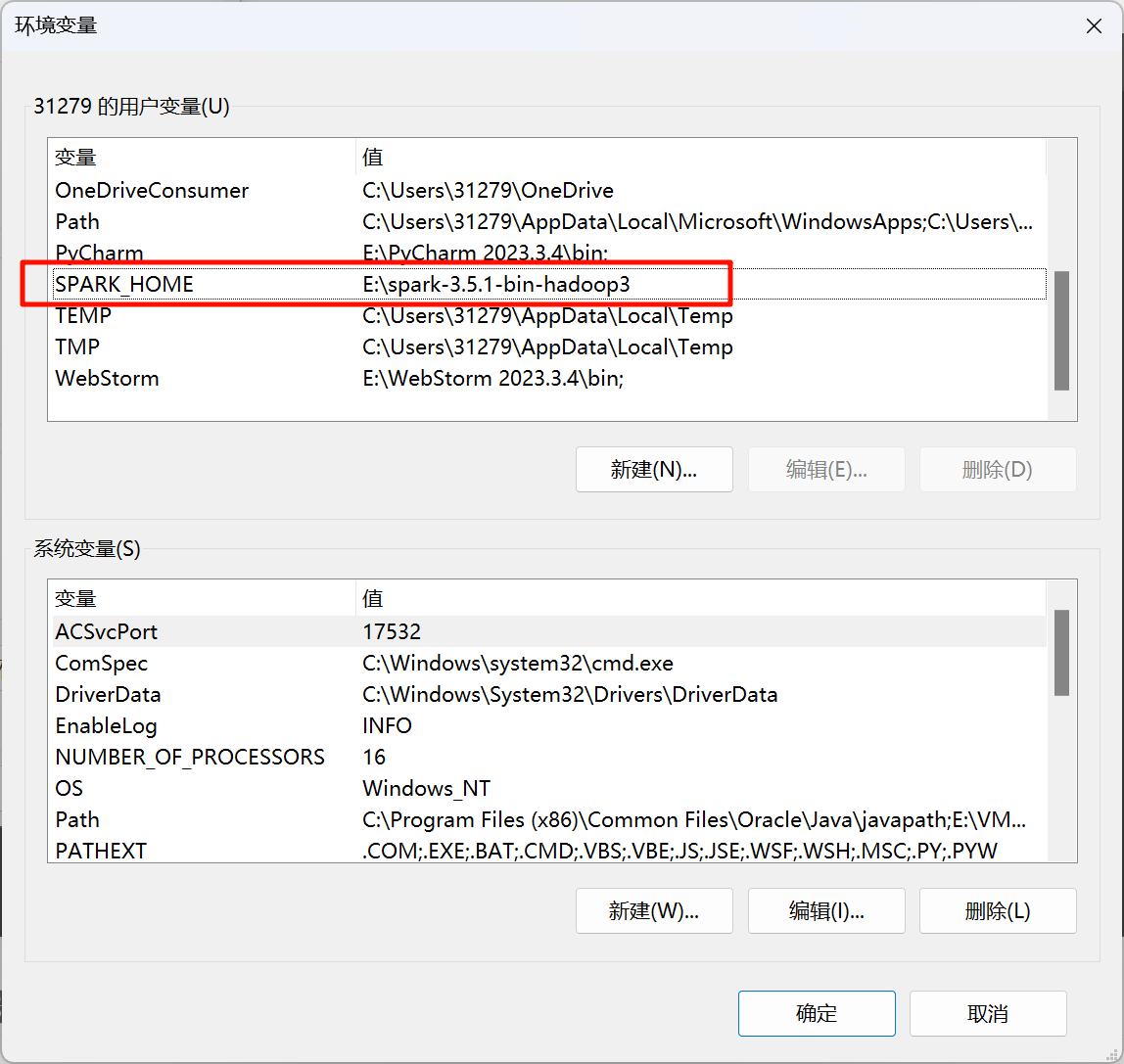
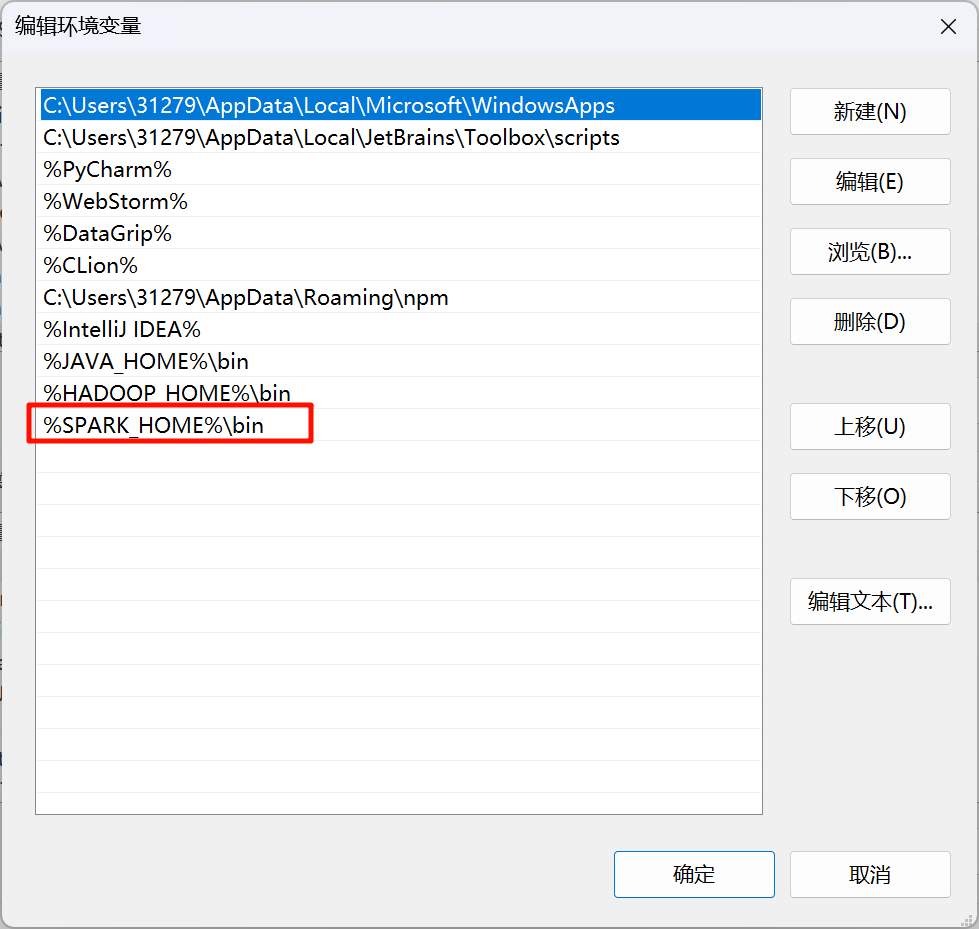
检查是否安装完成
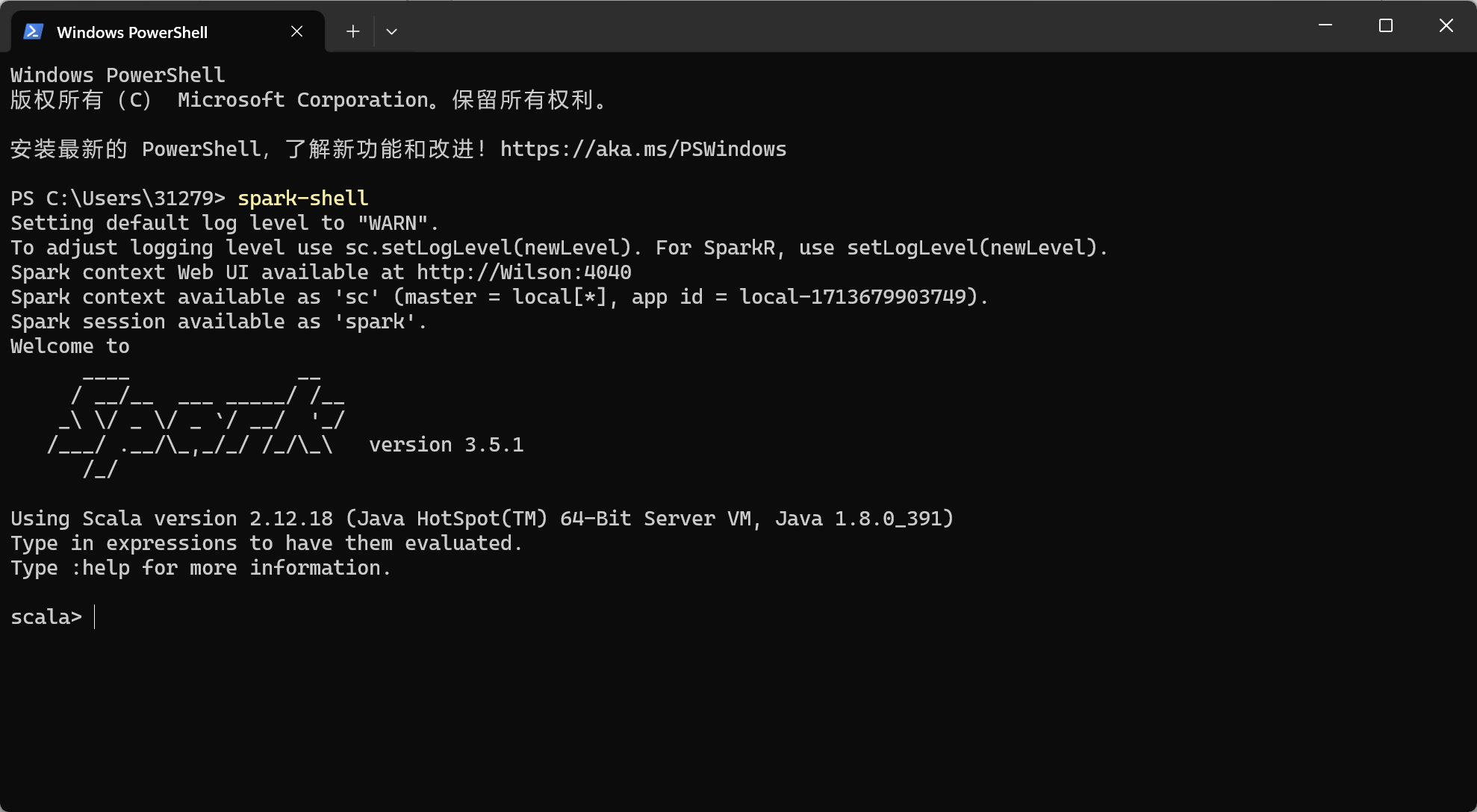
运行pyspark
在spark根目录python文件夹下运行pyspark
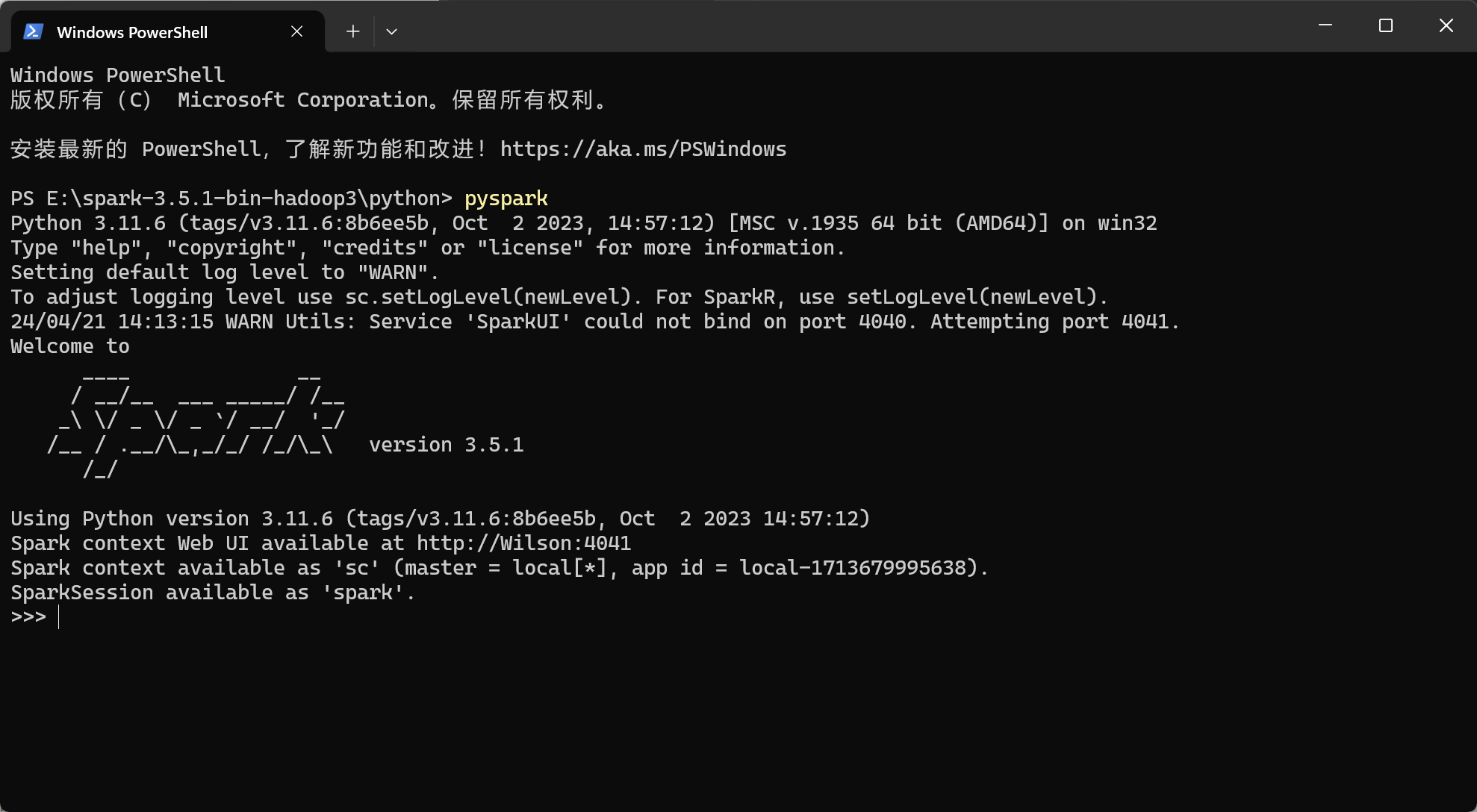
报错解决
Cannot create symbolic link : 客户端没有所需的特权。 : E:\hadoop-3.3.5\lib\native\libhdfspp.so
我使用7-zip解压Hadoop文件夹,但是报错
解决办法:已管理员身份运行7-zip对Hadoop文件夹解压缩,即可正常全部解压
java.io.IOException: NameNode is not formatted.
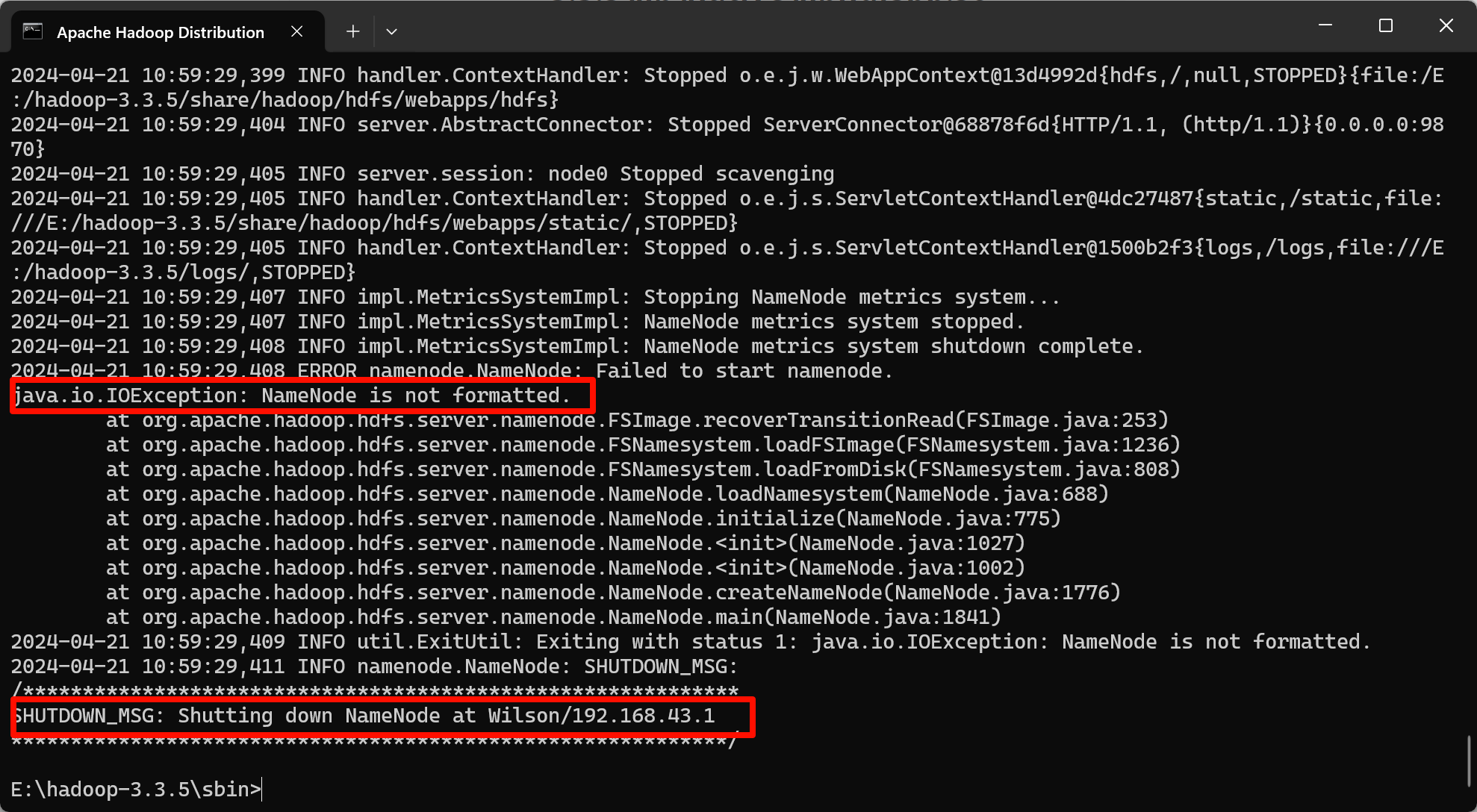
出现这个报错是指namenode没有初始化
解决办法,杀死所有进程后进行初始化,然后再start-all.cmd
NodeManager没有启动
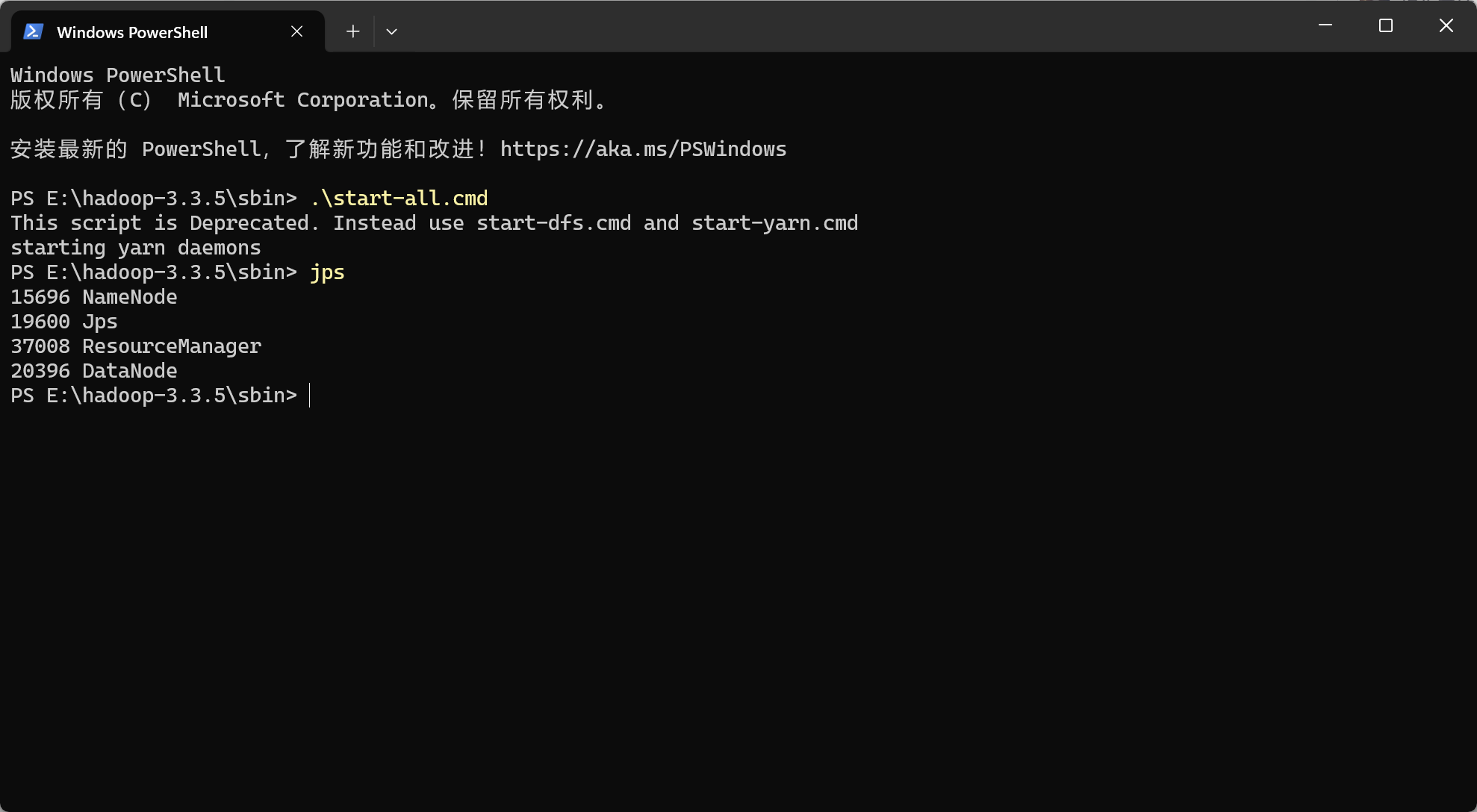
解决办法:添加yarn-site.xml文件配置,变成如下配置
xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
</configuration>补充的两条配置第一个是nodemanager运行时的最低内存,第二个是nodemanager运行时的cpu数量
修改后再次运行,发现还是报错
查找错误日志
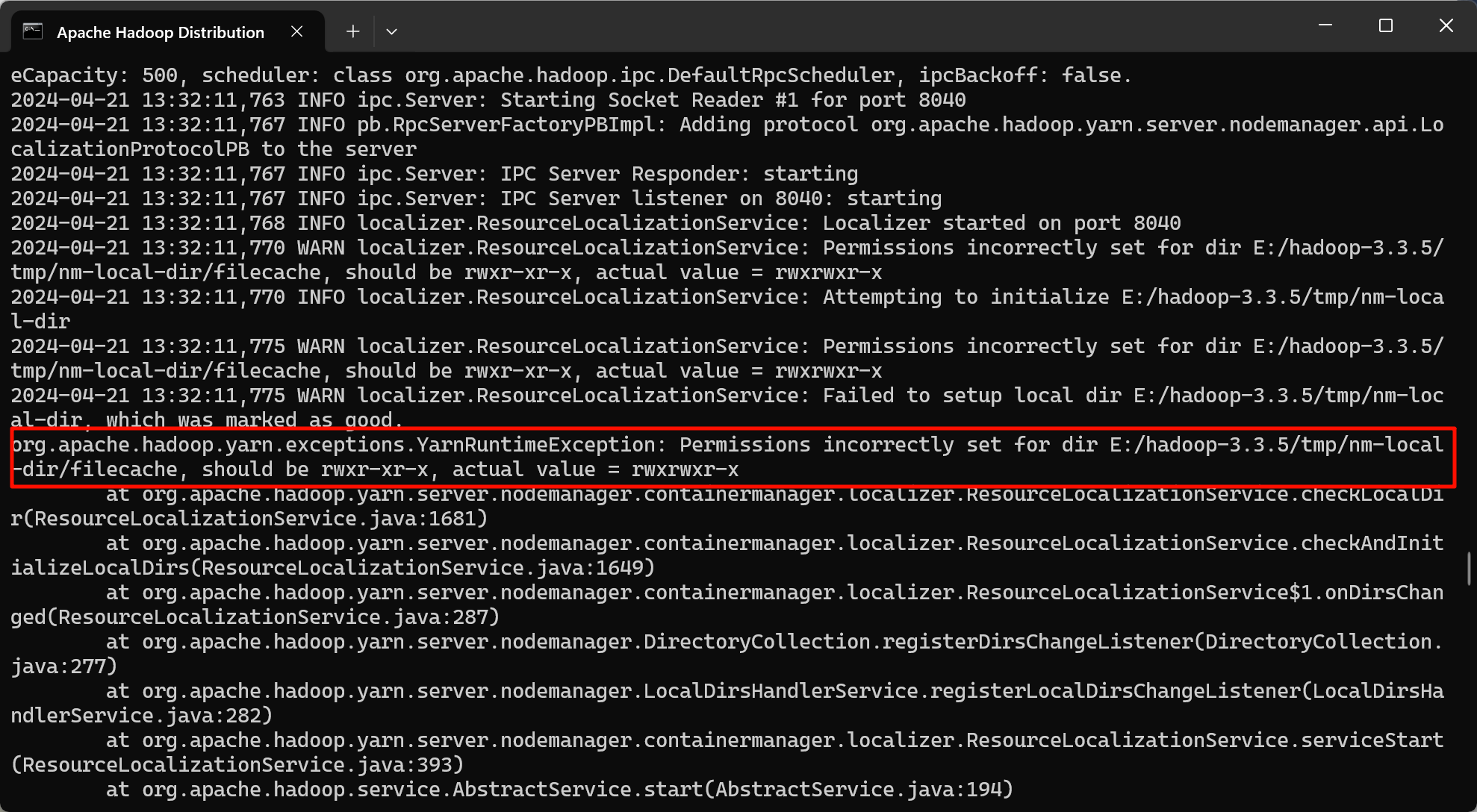
解决办法:运行start-all.cmd时需要以管理员身份运行cmd,即可正常运行